
前言
最近在整理视频内容,需要用到之前B站上传的一个视频集合内容的目录
要求如下:
1.提取目录的文字
2.在目录前加上序号(B站是不显示集数的)
分析网页格式
如图所示,图中位置就是我们需要提取的内容
其实是有一定规律的:
1.要么<div title=后面是视频标题
2.要么<div class="title-txt">后面是视频标题
所以我们有两种提取方法
<div title="社区使用方法 - 必看导学!" class="title"><div class="playing-gif" style="display:;"></div> <div class="title-txt">社区使用方法 - 必看导学!</div></div>
<div title="课前准备1-历史回顾与课前准备" class="title"><div class="playing-gif" style="display:none;"></div> <div class="title-txt">课前准备1-历史回顾与课前准备</div></div>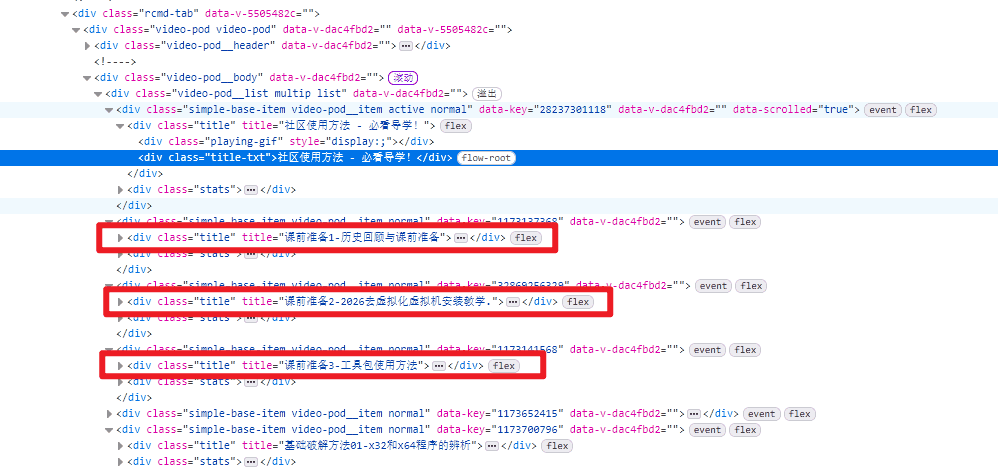
测试
在实际测试过程中,发现B站前两个是视频选集和广告内容,所以要忽略掉。


最终代码
import requests
from bs4 import BeautifulSoup
url = "https://www.bilibili.com/video/BV1FP411B7b7" # 替换成你关注的合集链接
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/xx Safari/xx"
}
resp = requests.get(url, headers=headers)
resp.encoding = 'utf-8'
soup = BeautifulSoup(resp.text, "html.parser")
titles = []
for div in soup.find_all("div", class_="title"):
# 尝试取 title 属性(通常是完整标题)
t = div.get("title", "").strip()
if not t:
# 如果没有 title 属性,则尝试取子 div 的文本
inner = div.find("div", class_="title-txt")
if inner:
t = inner.text.strip()
if t:
titles.append(t)
# 方法1:直接跳过前2个结果
print("方法1:跳过前2个结果")
for idx, t in enumerate(titles[2:], 1): # 从第3个开始,索引从1开始
print(idx, t)
# 方法2:先打印所有看看哪些是需要的
print("\n方法2:先查看所有结果")
for idx, t in enumerate(titles, 1):
print(f"{idx}: {t}")
print(f"\n总共有 {len(titles)} 个标题")
print("如果你需要的是从第3个开始,可以使用 titles[2:]")



没有回复内容