
缘由
我需要把里面的0x数字,全部替换为0x00,
如果是一个一个手动改,就太麻烦了,所以这个时候就可以用正则表达式
BYTE 新名称[] = { 0xD7,0xF7,0xD5,0xDF,0xA3,0xBA,0xB6,0xB6,0xD2,0xF4,0xBF,0xEC,0xCA,0xD6,0xD0,0xA1,0xBA,0xEC,0xCA,0xE9,0xCA,0xD3,0xC6,0xB5,0xBA,0xC5,0xA3,0xBA,0xC9,0xAB,0xD5,0xDF,0x41,0x49,0x0D,0x0A,0x65,0x63,0x68,0x6F,0x2E,0x0D,0x0A,0x65,0x63,0x68,0x6F,0x20,0xCD,0xF8,0xD5,0xBE,0xA3,0xBA,0x77,0x77,0x77,0x2E,0x73,0x65,0x7A,0x68,0x65,0x61,0x69,0x2E,0x63,0x6F,0x6D,0x0D,0x0A,0x65,0x63,0x68,0x6F,0x20,0xB1,0xB8,0xD7,0xA2,0xA3,0xBA,0x20,0xB8,0xFC,0xB6,0xE0,0xD7,0xD4,0xC3,0xBD,0xCC,0xE5,0x41,0x49,0xB9,0xA4,0xBE,0xDF,0xB0,0xFC,0xBF,0xC9,0xC7,0xB0,0xCD,0xF9,0xCE,0xD2,0xB5,0xC4,0xC6,0xB5,0xB5,0xC0,0xB2,0xE9,0xBF,0xB4,0x21,0x20,0xC1,0xBC,0xD0,0xC4,0xD5,0xFB,0xBA,0xCF,0xB7,0xD6,0xCF,0xED,0xA3,0xAC,0xBE,0xF8,0xCE,0xDE,0xCC,0xD7,0xC2,0xB7,0x21,0x0D,0x0A,0x65,0x63,0x68,0x6F,0x20,0xD3,0xCD,0xB9,0xDC,0xA3,0xBA,0x68,0x74,0x74,0x70,0x73,0x3A,0x2F,0x2F,0x77,0x77,0x77,0x2E,0x79,0x6F,0x75,0x74,0x75,0x62,0x65,0x2E,0x63,0x6F,0x6D,0x2F,0x40,0x73,0x65,0x7A,0x68,0x65,0x61,0x69,0x00,0x00,0x00,0x00,0x00,0x00,0x00 ,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00 };实践
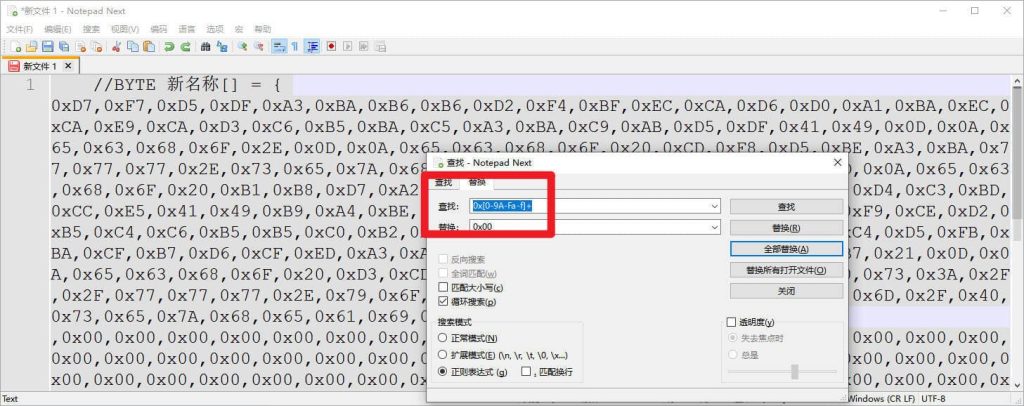
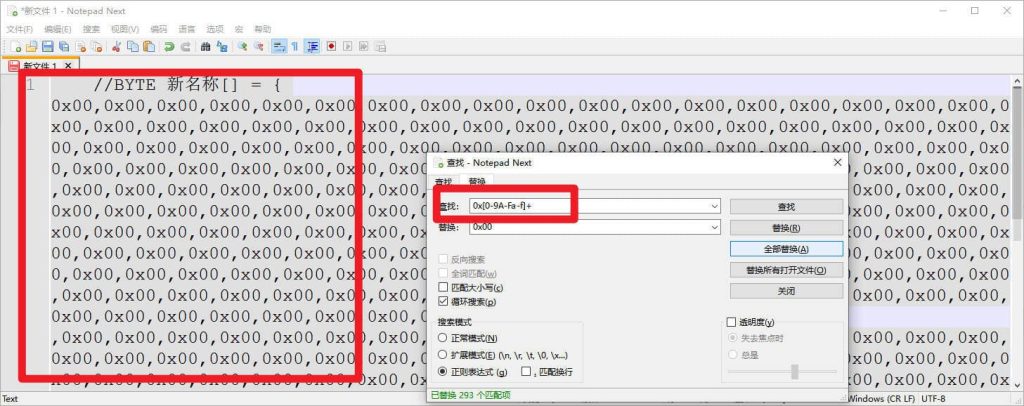
解析
0x[0-9A-Fa-f]+ 是一个正则表达式,用于匹配以 “0x” 开头的十六进制数。下面是对这个正则表达式的详细解释:
-
0x:这部分是十六进制数的常见前缀,用于指示接下来的数字是十六进制格式。在正则表达式中,它按照字面意思进行匹配,即查找包含 “0x” 的字符串。
-
[0-9A-Fa-f]:这是一个字符集,用于匹配十六进制数字中的任何一个字符。其中:
- 0-9:匹配任意一个十进制数字字符。
- A-F:匹配大写形式的十六进制字母(A 到 F)。
- a-f:匹配小写形式的十六进制字母(a 到 f)。
-
+:这是一个量词,表示前面的字符集(即
[0-9A-Fa-f])可以在字符串中出现一次或多次。这意味着,在 “0x” 之后,必须至少有一个十六进制数字字符,也可以有多个。
综上所述,0x[0-9A-Fa-f]+ 这个正则表达式用于匹配形如 “0x1A3F”、”0xFF” 或 “0x12345678” 的十六进制数。它不匹配没有前缀 “0x” 的十六进制数,也不匹配在 “0x” 之后没有十六进制数字字符的字符串。
这个正则表达式在编程和数据验证中非常有用,特别是在处理与计算机内存地址、颜色代码或其他需要以十六进制格式表示的数据时。
拓展
正则表达式确实是一种非常强大的文本处理工具,它用于模式匹配和字符串处理,能够帮助用户高效地处理各种文本数据。以下是一些常用的正则表达式及其应用场景:
匹配单个字符或字符集
.:匹配任意单个字符(除了换行符)。[...]:匹配方括号内的任意一个字符。例如,[abc]匹配 ‘a’、’b’ 或 ‘c’。[^...]:匹配不在方括号内的任意一个字符。例如,[^abc]匹配除了 ‘a’、’b’、’c’ 之外的任意字符。
匹配字符出现次数
*:匹配前一个字符零次或多次。例如,ab*c匹配 ‘ac’、’abc’、’abbc’ 等。+:匹配前一个字符一次或多次。例如,ab+c匹配 ‘abc’、’abbc’、’abbbc’ 等,但不匹配 ‘ac’。?:匹配前一个字符零次或一次。例如,ab?c匹配 ‘ac’ 或 ‘abc’。{n}:匹配前一个字符恰好 n 次。例如,a{2}b匹配 ‘aab’。{n,}:匹配前一个字符至少 n 次。例如,a{2,}b匹配 ‘aab’、’aaab’ 等。{n,m}:匹配前一个字符至少 n 次,但不超过 m 次。例如,a{2,4}b匹配 ‘aab’、’aaab’、’aaaab’,但不匹配 ‘ab’ 或 ‘aaaaab’。
匹配特定字符类型
\d:匹配一个数字字符(0-9)。\D:匹配一个非数字字符。\w:匹配一个单词字符(字母、数字或下划线)。\W:匹配一个非单词字符。\s:匹配一个空白字符(空格、制表符、换行符等)。\S:匹配一个非空白字符。
匹配字符串位置
^:匹配字符串的开始。$:匹配字符串的结束。
常用的正则表达式示例
-
校验数字
- 匹配正整数:
^\d+$ - 匹配负整数:
^-\d+$ - 匹配正浮点数:
^\d*\.\d+$ - 匹配负浮点数:
^-\d*\.\d+$ - 匹配非负整数(正整数和零):
^\d+$ - 匹配非正整数(负整数和零):
^-\d+|0$ - 匹配非负浮点数(正浮点数和零):
^\d+(\.\d+)?$ - 匹配非正浮点数(负浮点数和零):
^(-\d+(\.\d+)?|0(\.0+)?)$
- 匹配正整数:
-
校验字符
- 匹配电子邮件地址:
^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\.[a-zA-Z0-9-.]+$ - 匹配URL:
^(https?|ftp)://[^\s/$.?#].[^\s]*$ - 匹配国内手机号(中国):
^1[3-9]\d{9}$ - 匹配用户名(允许字母、数字、下划线,3到16位):
^[a-zA-Z0-9_]{3,16}$ - 匹配强密码(至少8个字符,至少一个数字和一个字母):
^(?=.*[A-Za-z])(?=.*\d)[A-Za-z\d]{8,}$
- 匹配电子邮件地址:
-
其他常用
- 匹配国内电话号码(座机):
^\d{3,4}-\d{7,8}$ - 匹配IP地址:
\b(?:\d{1,3}\.){3}\d{1,3}\b - 匹配MAC地址:
^([0-9A-Fa-f]{2}:){5}[0-9A-Fa-f]{2}$ - 匹配日期(YYYY-MM-DD):
^\d{4}-\d{2}-\d{2}$ - 匹配时间(HH:MM:SS):
^\d{2}:\d{2}:\d{2}$ - 匹配日期(MM/DD/YYYY或MM-DD-YYYY):
^(0[1-9]|1[0-2])[\/\-](0[1-9]|[12][0-9]|3[01])[\/\-]\d{4}$ - 匹配时间(24小时制,HH:MM):
^([01]\d|2[0-3]):[0-5]\d$ - 匹配邮政编码(国际):
^\d{4,6}$ - 匹配URL(不带协议):
^[^\s/$.?#].[^\s]*$ - 匹配RGB颜色代码:
^#?([a-fA-F0-9]{6}|[a-fA-F0-9]{3})$
- 匹配国内电话号码(座机):
-
特殊情况
- 匹配HTML标签:
^<([a-z]+)([^<]+)*(?:>(.*)<\/\1>|\s+\/>)$ - 匹配包含中文字符的字符串:
[\u4e00-\u9fa5] - 匹配括号内的内容:
$([^)]+)$ - 匹配引号内的内容:
"([^"]*)"或'([^']*)' - 匹配Markdown链接:`
- 匹配HTML标签:
`
- 匹配CSV文件中的一行:
^(?:[^,]*,)*[^,]*$ - 匹配美元金额(如123.45):`^\\d+(.\d{2})?$`
正则表达式非常灵活和强大,通过组合不同的元字符和量词,可以构建出各种复杂的匹配模式。不过,正则表达式的语法有时可能会显得复杂和难以阅读,因此在实际应用中,建议根据具体需求选择合适的正则表达式,并尽量保持其简洁和易读。



没有回复内容